MQ框架
RocketMQ
1. 简介
分布式消息中间件,阿里巴巴捐赠给 Apache 社区的开源项目 RocketMQ从Apache社区正式毕业,成为 Apache 顶级项目(TLP)
纯Java开发
RocketMQ 都承载着阿里巴巴生产系统 100% 的消息流转,以去年双 11 为例的, RocketMQ 完成了 1.2 万亿消息精准低延迟投递,交易峰值高达 17 万笔/秒。
2. 特性
- 低延迟、高并发:99.6% 以上的响应延迟在 1 毫秒以内
- 面向金融:满足跟踪和审计的高可用性
- 工业级适用:可确保万亿量级的消息发送
- 中立性:支持多种消息传递协议,如 JMS 和 OpenMessaging
- 性能可靠:给予足够的磁盘空间,消息可以累积存放而没有性能损失。
RabbitMQ (DXP项目用过)
1. AMQP
包括以下组件:
Server(Broker): 接受客户端连接,实现消息队列和路由功能。
Virtual Host: 类似于权限控制组,一个Virtual Host里面可以有若干个Exchange和Queue,但是权限控制的最小粒度是Virtual Host
Exchange: 接受生产者发送的消息,并根据Binding规则将消息路由给服务器中的队列。ExchangeType决定了Exchange路由的消息行为,例如,在RabbitMQ中,ExchangeType有direct、Fanout和Topic三种,不同类型的Exchange路由的行为是不一样的。
Message Queue:消息队列,用于存储还未被消费者消费的消息。
Message: 由Header和Body组成,Header是由生产者添加的各种属性的集合,包括Message是否被持久化、由哪个Message Queue接受、优先级是多少等。而Body是真正需要传输的APP数据。
Binding: 联系了Exchange与Message Queue。Exchange在与多个Message Queue发生Binding后会生成一张路由表,路由表中存储着Message Queue所需消息的限制条件即Binding Key。当Exchange收到Message时会解析其Header得到Routing Key,Exchange根据Routing Key与Exchange Type将Message路由到Message Queue。Binding Key由Consumer在Binding Exchange与Message Queue时指定,而Routing Key由Producer发送Message时指定,两者的匹配方式由Exchange Type决定。
Connection: 连接,对于RabbitMQ而言,其实就是一个位于客户端和Broker之间的TCP连接。
Channel: 信道,仅仅创建了客户端到Broker之间的连接后,客户端还是不能发送消息的。需要为每一个Connection创建Channel,AMQP协议规定只有通过Channel才能执行AMQP的命令。一个Connection可以包含多个Channel。之所以需要Channel,是因为TCP连接的建立和释放都是十分昂贵的,如果一个客户端每一个线程都需要与Broker交互,如果每一个线程都建立一个TCP连接,暂且不考虑TCP连接是否浪费,就算操作系统也无法承受每秒建立如此多的TCP连接。RabbitMQ建议客户端线程之间不要共用Channel,至少要保证共用Channel的线程发送消息必须是串行的,但是建议尽量共用Connection。
Command: AMQP的命令,客户端通过Command完成与AMQP服务器的交互来实现自身的逻辑。例如在RabbitMQ中,客户端可以通过publish命令发送消息,txSelect开启一个事务,txCommit提交一个事务。

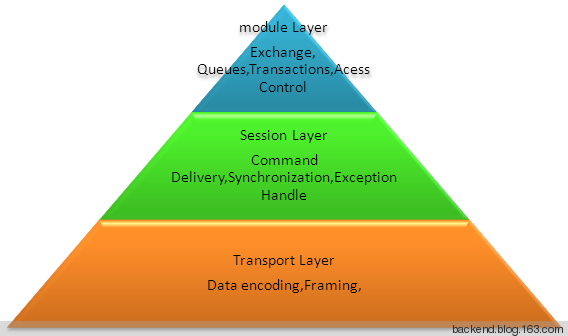
AMQP协议本身包括三层:
Module Layer,位于协议最高层,主要定义了一些供客户端调用的命令,客户端可以利用这些命令实现自己的业务逻辑,例如,客户端可以通过queue.declare声明一个队列,利用consume命令获取一个队列中的消息。
Session Layer,主要负责将客户端的命令发送给服务器,在将服务器端的应答返回给客户端,主要为客户端与服务器之间通信提供可靠性、同步机制和错误处理。
Transport Layer,主要传输二进制数据流,提供帧的处理、信道复用、错误检测和数据表示。
2. 简介
开源的AMQP(高级消息队列协议)实现
服务器端用Erlang语言编写,支持多种客户端
Erlang是一种通用的面向并发的编程语言,目的是创造一种可以应对大规模并发活动的编程语言和运行环境。
- 属于多重范型编程语言,涵盖函数式、并发式及分布式。
- 结构化,动态类型编程语言,内建并行计算支持。
- 使用Erlang编写出的应用运行时通常由成千上万个轻量级进程组成,并通过消息传递相互通讯。
- 进程间上下文切换对于Erlang来说仅仅 只是一两个环节,比起C程序的线程切换要高效得多得多了。
- Erlang运行时环境是一个虚拟机,有点像Java虚拟机,这样代码一经编译,同样可以随处运行。
- 它的运行时系统甚至允许代码在不被中断 的情况下更新。
- 另外如果需要更高效的话,字节代码也可以编译成本地代码运行。
Erlang特性:
- 并发性 - Erlang支持超大量级的并发进程,并且不需要操作系统具有并发机制。
- 分布式 - 一个分布式Erlang系统是多个Erlang节点组成的网络(通常每个处理器被作为一个节点)
- 健壮性 - Erlang具有多种基本的错误检测能力,它们能够用于构建容错系统。
- 软实时性- Erlang支持可编程的”软”实时系统,使用了递增式垃圾收集技术。
- 热代码升级-Erlang允许程序代码在运行系统中被修改。旧代码能被逐步淘汰而后被新代码替换。在此过渡期间,新旧代码是共存的。
- 递增式代码装载-用户能够控制代码如何被装载的细节。
- 外部接口-Erlang进程与外部世界之间的通讯使用和在Erlang进程之间相同的消息传送机制。
- Fail-fast(中文译为速错),即尽可能快的暴露程序中的错误。
- 面向并发的编程(COP concurrency-oriented programming)
- 函数式编程
- 动态类型
- 及早求值或严格求值
- 支持脚本运行
高可用性
提供消息持久化
3. 使用场景
场景1:单发送单接收
场景2:单发送多接收
场景3:Publish/Subscribe
使用场景:发布、订阅模式,发送端发送广播消息,多个接收端接收。
场景4:Routing (按路线发送接收)
使用场景:发送端按routing key发送消息,不同的接收端按不同的routing key接收消息。
- exchange的type为direct
- 发送消息的时候加入了routing key
在绑定queue和exchange的时候使用了routing key,即从该exchange上只接收routing key指定的消息。
场景5:Topics (按topic发送接收)
使用场景:发送端不只按固定的routing key发送消息,而是按字符串”匹配”发送,接收端同样如此。
- exchange的type为topic
- 发送消息的routing key不是固定的单词,而是匹配字符串,如”*.lu.#”,*匹配一个单词,#匹配0个或多个单词。
4. RabbitMQ分布式集群架构
5. 问题解决
- rabbitmq堆积消息后生产速率降低的问题
在rabbitmq没有消费者的情况下,生产者持续向mq发消息,使得消息在mq中大量堆积,发送速率不受影响,但当有新的消费者连接上mq并开始接收消息时,生产速率大幅降低。
应对措施:
- 打破发送循环条件。
- (1) 设置合适的qos值,当qos值被用光,而新的ack未被mq接收时,就可以跳出发送循 环,去接收新的消息。
- (2) 消息者到主动block接收进程,消费者感知到接收消息的速度过快时,主动block,利用 block与unblock方法调节接收速率。当接收进程被block时,mq跳出发送循环。
- 建立新的队列 若服务器cpu资源有较多剩余,而又不需要保证消息的顺序的情况下可以通过建立新的vhost,在该vhost下创建queue,生产者将消息发送掉新的queue,消费者同时订阅新旧queue。
- 使用缓存 在生产者端使用缓存,当生产速率受到流控限制时,缓存数据。在堆积的消息被处理完后,生产速率恢复正常时,此时将缓存的数据发送给MQ。
- 更新rabbitmq版本
- 加机器。
RabbitMQ,ActiveMq,ZeroMq比较
1. TPS比较
ZeroMq 最好,RabbitMq 次之, ActiveMq 最差

2. 持久化消息比较
ZeroMq不支持,ActiveMq和RabbitMq都支持
3. 可靠性、灵活的路由、集群、事务、高可用的队列、消息排序、问题追踪、可视化管理工具、插件系统、社区
RabbitMq最好,ActiveMq次之,ZeroMq最差
虽然ActiveMQ也具备,但是它性能不及RabbitMQ
4. 高并发
RabbitMQ最高,原因是它的实现语言是天生具备高并发高可用的erlang语言
5. 综合来看,RabbitMQ是首选
淘宝使用RabbitMQ的心得,可以参看一些业务场景。
Kafka/Jafka和RabbitMQ的比较
关于Kafka/Jafka
Jafka是在Kafka之上孵化而来的,即Kafka的一个升级版
- 更快!单机上万TPS
- 用topic来进行消息管理,每个topic包含多个part,每个part对应一个逻辑log,有多个segment组成。
- segment中的消息id由其逻辑位置决定,可以用消息id直接定位到消息的存储位置,避免id到位置的额外映射。
- 生产者发到某个topic的消息会被均匀的分布到多个part上,broker收到消息会写入最后的segment文件中,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息消费者才能收到。并且通过rolling的机制,保证segment的文件不至于过大。
- 消费者可以rewind back到任意位置重新进行消费,当消费者故障时,可以选择最小的offset进行重新读取消费消息。
一些深坑
- Kafka对消息的重复、丢失、错误以及顺序型没有严格的要求。但是part只会被consumer group内的一个consumer消费,故kafka保证每个parti内的消息会被顺序的消费。
- broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。同时broker是无状态的,broker不保存消费者的状态,由消费者自己保存。无状态导也致消息的删除成为难题,所以Kafka选择消息保存一定时间后会被删除。
- 大量的依赖Zookeeper,需要Zookeeper来管理broker与consumer的动态加入与离开。以及消费关系及每个partion的消费信息。
特定故障场景
- Kafka大量依赖Zookeeper,它的broker并不保存任何状态,如果Zookeeper集群不幸悲剧了,那么整个Kafka集群的消息就全完蛋了。
- 当一个broker当机了整个消息队列由于负载均衡的算法,在一瞬间消费者和生产者之间的消息就全乱掉了。很多需要保证消息顺序的系统一下子就完蛋了。
比较总结
1. RabbitMq比kafka成熟,在可用性上,稳定性上,可靠性上,RabbitMq超过kafka
安全性和易用性都是RabbitMQ的强项
2. Kafka设计的初衷就是处理日志的,可以看做是一个日志系统,针对性很强,所以它并没有具备一个成熟MQ应该具备的特性
3. Kafka的性能(吞吐量、tps)比RabbitMq要强
100k/sec性能往往是人们选择 Apache Kafka的关键驱动力
20K/sec是很容易使用一个Rabbit队列实现的
使用建议
RabbitMQ该怎么用
- RabbitMQ的消息应当尽可能的小,并且只用来处理实时且要高可靠性的消息。
- 消费者和生产者的能力尽量对等,否则消息堆积会严重影响RabbitMQ的性能。
- 集群部署,使用热备,保证消息的可靠性。
Kafka该怎么用
- 应当有一个非常好的运维监控系统,不单单要监控Kafka本身,还要监控Zookeeper。
- 对消息顺序不依赖,且不是那么实时的系统。
- 对消息丢失并不那么敏感的系统。